
![]()
Our lab’s research unifies three learning-related areas —educational neuroscience, machine learning for special educational needs (SEN), and intervention—and focuses on (1) understanding the mechanism that enables children to crack suprasegmental speech and orthographic codes in two different languages to formulate speech-print associations in the process of becoming biliterate; (2) automizing the classification and diagnosis of special educational needs; and (3) developing cutting-edging, evidence-based, multi-modal clinical and educational practices for children.
Over 10 years of our lab’s work has culminated in theoretical models that inform the practice of clinicians and educators regarding the links between speech, language, and reading. These models are illustrated below.
1. The Prosodic Catalyzing Hypothesis (PCH)

Figure 1. The Prosodic Catalyzing Hypothesis (PCH)
(“The Roles of Prosody in Chinese-English Reading Comprehension” by Tong, S. X., Tsui, R. K., Law, N. S., Fung, L. S., Chiu, M. M., & Cain, K. in Learning and Instruction, 2023)
In this study, we propose and test the Prosodic Catalysing Hypothesis (PCH) which frames comprehension as a data-prediction and optimization problem. Comprehenders utilize implicit prosody or covert imitation to predict words, syntactic structure, and meanings. Simultaneously, prosodic reading reinforces this process by facilitating the transfer of prosodic cues that best match the prediction.
To test our hypothesis, we analyze the production of six types of parallel L1 and L2 syntactic structures in Cantonese-English bilingual children and their relation to reading comprehension. Our results demonstrate that these children are aware of both language-independent functions and language-specific manifestations of pitch and pause cues in their L1 Chinese and L2 English. We found that wh question pitch contours emerge as the most significant link to reading comprehension in both languages, while Cantonese pitch influences English reading comprehension. Additionally, certain pause structures are associated with English reading comprehension.
2. A Schematic Framework that Combines Reading Theory and Machine Learning to Classify and Predict Reading Status of Children
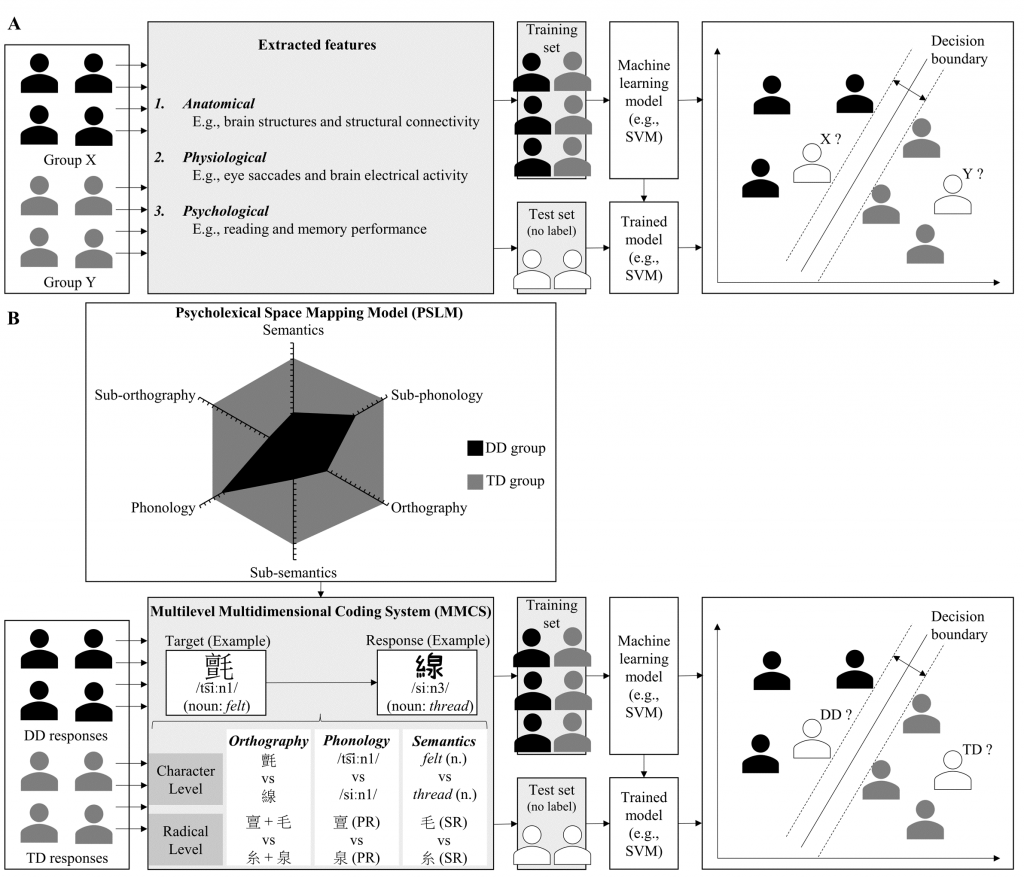
Figure 2. A schematic framework for classifying and predicting reading status of individuals combining reading theory and machine learning
(“Identifying Chinese Children with Dyslexia Using Machine Learning with Character Dictation” by Lee, S. M. K., Liu, H. W., & Tong, S. X. in Scientific Studies of Reading, 2022)
Panel A: A general flow of using supervised machine learning algorithms (e.g., SVM) for classification. Panel B: A specific flow for identifying dyslexia combining reading theories and machine learning algorithms. Guided by PSLM (Tong & McBride, 2018), MMCS was developed to analyze each written response in terms of orthography, phonology, and semantics at character and subcharacter (i.e., radical) levels (Lee & Tong, 2020). SVM = support vector machine; PR = phonetic radical; SR = semantic radical; DD = developmental dyslexia; TD = typically developing.
3. Statistical Learning and Reading Model (SLR)
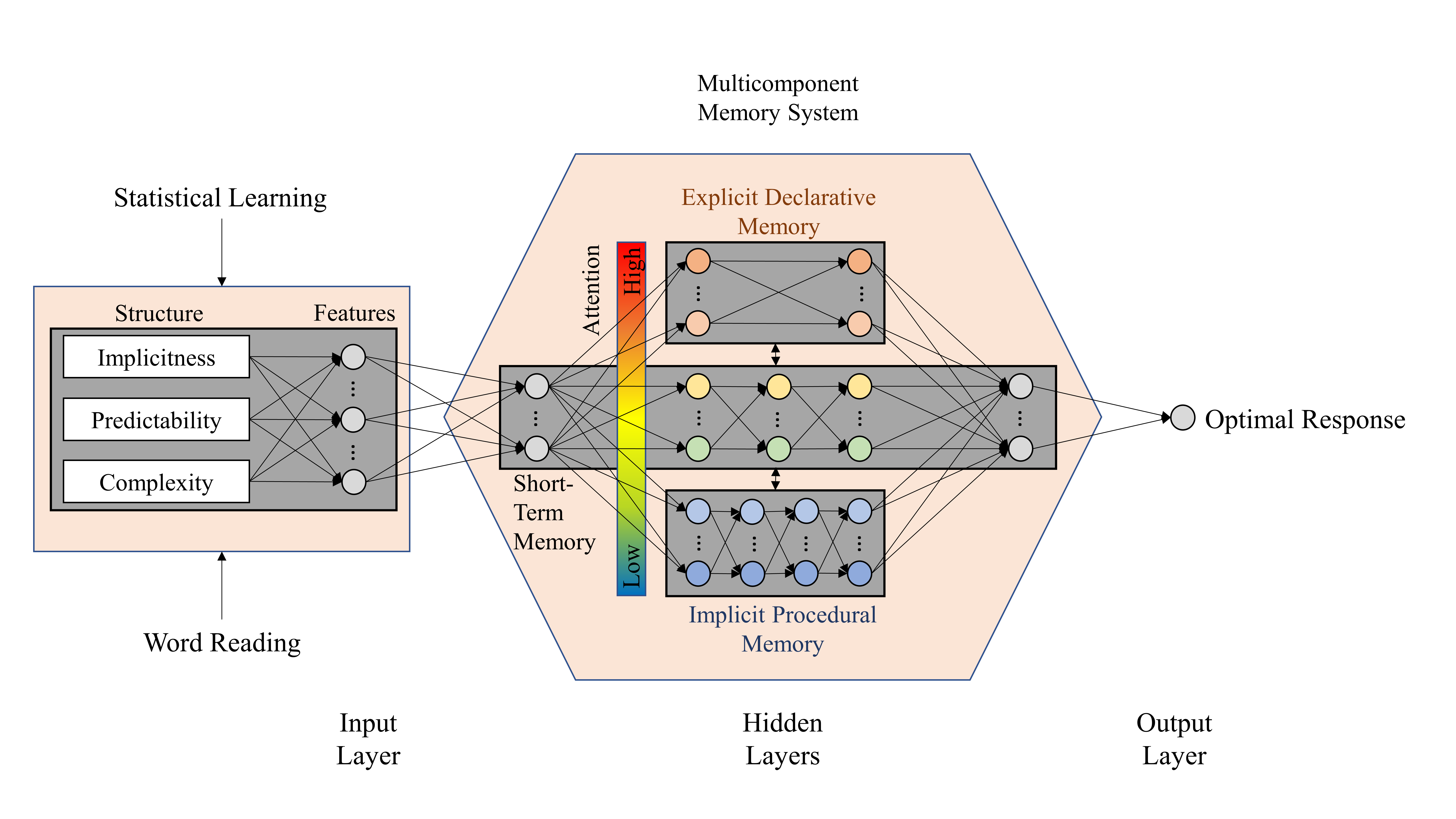 Figure 3. A statistical learning and reading model
Figure 3. A statistical learning and reading model
(“Toward a Model of Statistical Learning and Reading: Evidence From a Meta-Analysis” by Lee, S. M. K., Cui, Y., & Tong, S. X. in Review of Educational Research, 2022)
The SLR model comprises an input layer, a multicomponent memory network, and an output layer. The input layer encodes a range of acoustic-temporal and visual-spatial features that are regulated by a structure system quantifying the level of quasi-regularity indexed by the implicitness, predictability, and complexity of sensory input across modalities. The multicomponent memory network represents an interconnecting domain-general system that consists of a short-term memory subsystem, an explicit declarative long-term memory subsystem, and an implicit procedural long-term memory subsystem. The short-term memory subsystem enables temporary storage of incoming and ongoing information. The two long-term memory subsystems differ in terms of the attentional demands required for encoding and storage of information, with more controlled attention (i.e., a top-down selective attention to learning stimuli) than automatic attention (i.e., a bottom-up involuntary attention to salient stimuli) needed in the explicit declarative subsystem, and, conversely, more automatic attention than controlled attention needed in the implicit procedural subsystem. The color bar indicates the activation level of controlled attention, ranging from low (blue) to high (orange). The model output is a statistically optimal representation as manifested by the neural and behavioural response of statistical learning and reading activities.
4. Graded Psycho-lexical Space Mapping Model of Chinese Character Processing (PLSM)
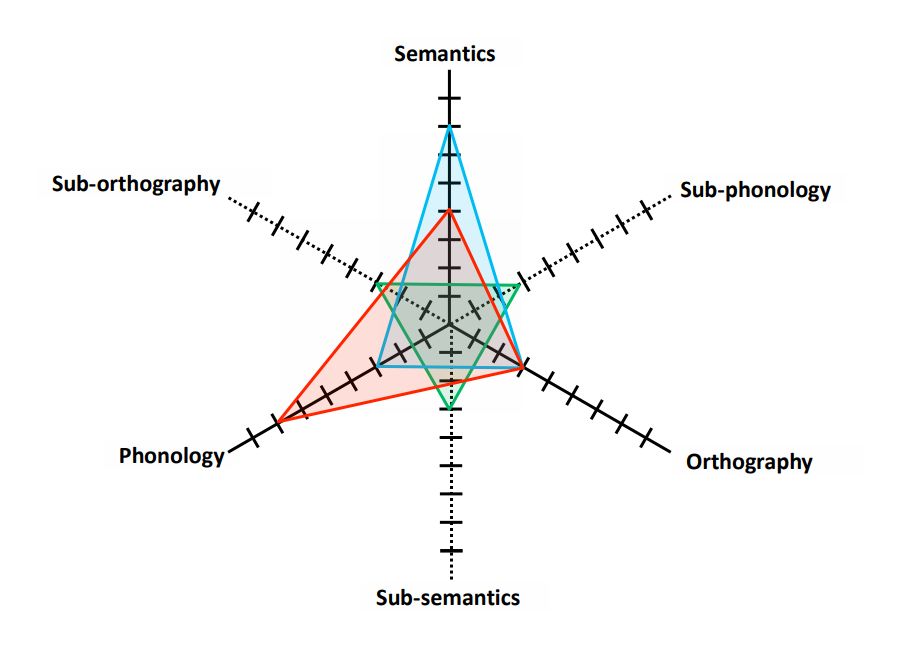
Figure 4. Graded psycho-lexcial space mapping model of Chinese character processing
(“Toward a graded psycholexical space mapping model: Sublexical and lexical representations in Chinese character reading development” by Tong, S. X. & McBride, C. in Journal of Learning Disabilities, 2018)
5. Statistical Learning of Orthographic Regularities (SLOR)

Figure 5. A model of statistical learning of Chinese orthographic regularities
(“Statistical Learning as a Key to Cracking Chinese Orthographic Codes” by He, X. & Tong, S. X. in Scientific Studies of Reading, 2017)
6. NCCP Model
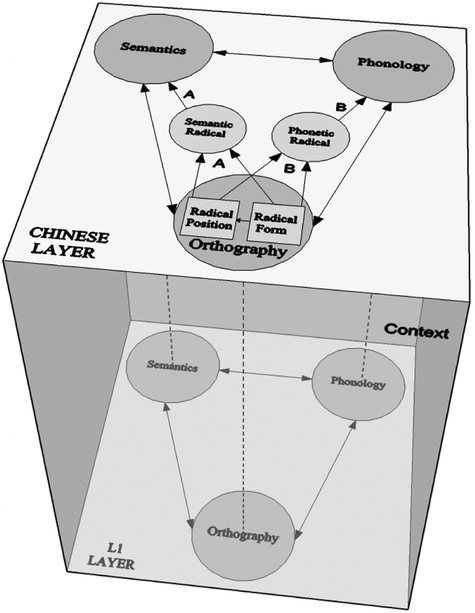
Figure 6. Non-native Chinese character processing model
(“Toward a dynamic interactive model of non-native Chinese character processing” by Tong, X., Kwan, J. L. Y., Wong, D. W. M., Lee, S. M. K., & Yip, J. H. Y. in Journal of Educational Psychology, 2016)
7. TTRACE Model
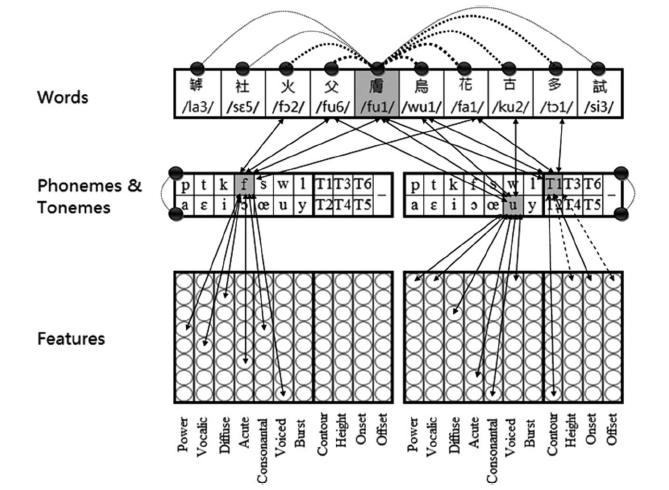
Figure 7. The TTRACE model for speech perception of tonal languages
(“Cues for Lexical Tone Perception in Children: Acoustic Correlates and Phonetic Context Effects” by Tong, X., McBride, C., & Burnham, D. in Journal of Speech, Language and Hearing Research, 2014)